




Creating a Collaborative Editor
In our day and age, people are able to work together despite being in completely different parts of the world. Writing is central to most businesses today, and products like Google Docs makes it possible to collaborate with ease. I will explain how it's possible to create a collaborative editor that can guarantee consistency.
UPDATE 2021-04-11:
Although this is a decent introduction to the problems involved when creating a collaborative editor. This editor is not suitable for production use, as there are solutions which have better performance. This solution doesn't support interleaving, which Martin Kleppman explains here. A better solution that is based of CRDT WOOT can be found here.

What makes a collaborative editor different than regular ones is that they are able to keep a consistent state, even though multiple users are typing simultaneously. Even if multiple users are hammering away, smashing their keyboards, the state is kept consistent.
This problem has been researched for a long time. Since the 1980s according to Google Scholar. What makes this problem difficult is that you have to guarantee consistency. There should be no corner cases were two editors diverge into an inconsistent state. Many attempts have been proposed to solve this issue. Operational Transformation (OT) is one of those algorithms, which have been evolving over time, as versions of it have been proven incorrect. I will use another algorithm though.
Conflict-Free Replicated data type (CRDT) can be used to replicate data between multiple replicas and guarantee that they converge to the same state. That's quite a mouthful, I know, bear with me. It can be used in a variety of different types of systems, including working with documents.
In a collaborative editor, changes are continuously sent between users and merged such that the document that each user is working with is consistent with each other. But since the editors are being used on the internet, we can't guarantee true consistency, since latency is unavoidable, hence only eventual consistency can be guaranteed. It basically means that eventually, the replicas will be consistent with each other if the edits are stopped at some point, and the replicas are able to process the edits.
In order to guarantee eventual consistency, we have to use a proven algorithm, such as OT or CRDT. I have chosen CRDT since I think they are easier to understand and reason about.
CRDT follow three mathematical properties:
Commutative: ab=ba
Associative: (ab)c = a(bc)
Idempotent: (a*a) = a
- = binary operation, example: max or union.
Because they follow these rules, they are guaranteed to be consistent. Associativity and commutativity make it possible to apply edits in a different order but arrive in the same state, regardless of in which order they were applied. The idempotent property says that if you apply the same edit multiple times, the result should be the same. These three properties combined constructs a join-semilattice. In a previous post, I described this concept in-depth. Warning, this is a rabbit hole, if you truly want to understand all these properties fully, you better get your coffee ready. ☕
There exist two different kinds of CRDTs, one is state-based, where the whole state is sent between replicas and merged continuously. The other one is operation-based, were only individual operations are sent between replicas. In my editor, I opted for the operation-based one, since the state can grow and become expensive to send down the wire.
CRDT Sequence
A CRDT Sequence can be represented as a sequence of characters in a list, where each character has a unique global index. Meaning the index will be the same for all users. We have a list, and it will be the same for all users, even if two users make an insert at the same index, a “conflict” occurs, the tiebreaker is solved by figuring out which user has the lowest user id. So each user is given a unique user id (UUID), that solves any conflict.
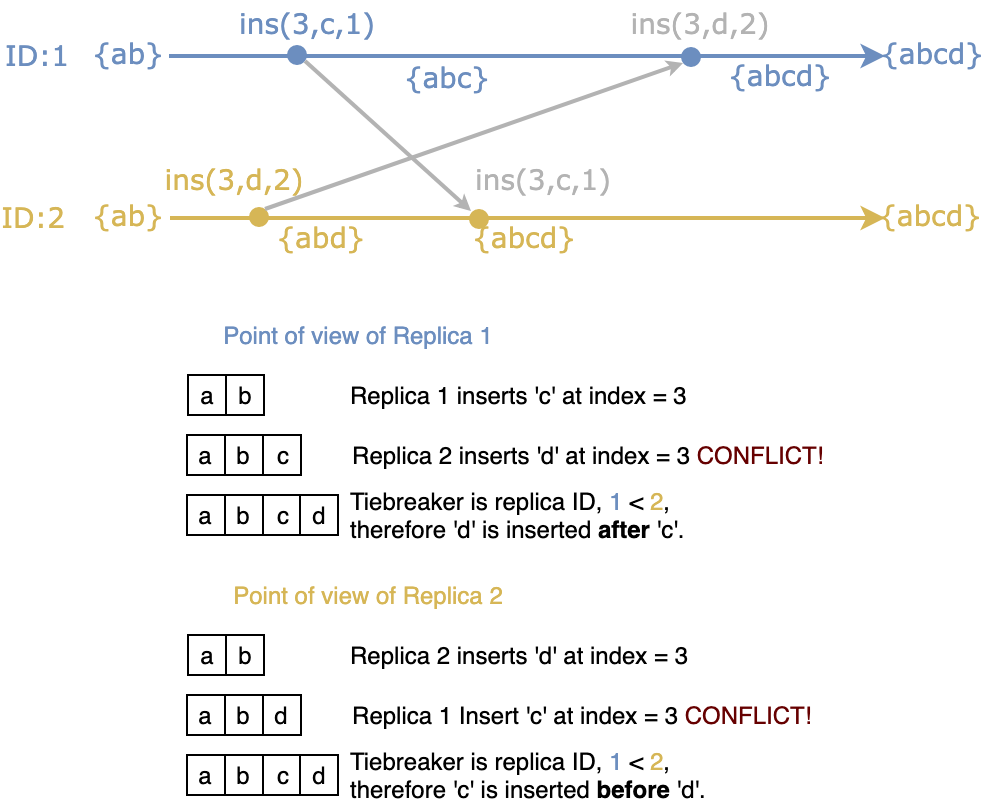
Let's go over an example. Two users (blue and yellow) are editing together, both users have a UUID. Both users start with the sequence "ab". The blue user with UUID of 1 decides to make an insert "c" at index 3. Simultaneously the yellow user with UUID of 2 inserts "d" at index 3. Changes are sent between the users, but due to delays, they arrive in a different order.
The blue user receives the insert of "d" at index 3. But there already exists a character at index 3, the tiebreaker here is the UUID, as the yellow user has a higher UUID, its insert will be added after the letter "c".
The yellow user receives the insert of "c" at position 3, but it already has a character at index 3, since the blue user has a lower id, "c" will be inserted before "d". Both users arrive in the same state, which is "abcd". Even though the changes were applied in a different order, and were in conflict with each other.
Inserts of characters
In the above example, both users arrived at the same state eventually (eventual consistency), even though temporarily they saw different characters on their screens. The blue user first saw "abc" followed by "abcd", and the yellow user saw "abd" followed by "abcd".
The deletion of characters in a CRDT Sequence is very simple. By marking a character as removed, using a tombstone, the character can simply not be rendered in the editor. But the character is still present in the CRDT Sequence. It can not yet be removed since the CRDT is bound by mathematical properties that must be followed.
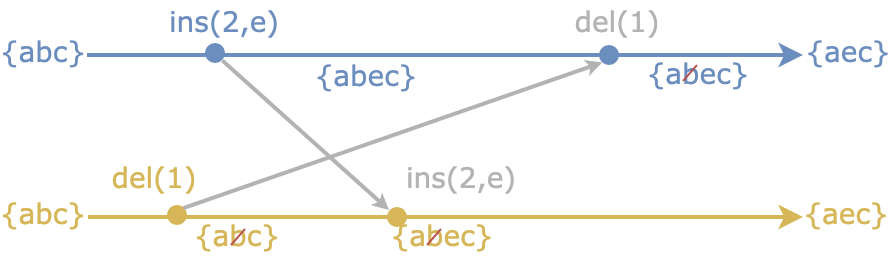
The obvious downside of this is that our document might potentially be filled with a bunch of characters that are removed, but not seen in the editor, causing unbounded memory growth.
While these operations are occurring we have to keep in mind that users might be disconnected from the server. Therefore it's necessary to be able to bring the user back to a consistent state when they connect again. Version Vectors can be used to solve this problem. Its a vector that counts how many changes are made by each user. Each user stores their own local version vector. This vector can be compared with other vectors to see which changes are missing and needs to be seent to some user.
Implementation
I used React because it works well for what I am trying to do, but by no means necessary. A central server was used which can store the document, and synchronize data between users, acting as a middleman, receiving incoming changes, and distribute these to connected users. I used WebSockets to send and receive change from the client and the server. On the server, I opted for a simple Express + Node.JS server.
CRDTs can be used in a peer-to-peer network model, which I did not do. The team behind Conclave created a peer-to-peer collaborative editor and described their implementation in a well-written article.
Rich text editor (Quill)
Quill is an open source rich-text editor. Covering the basic functionally of an editor. Its API documentation is well written, which is very important in order to integrate it successfully with the CRDT model. There also exists a React-Quill npm package, which helped a bit too.
Quill
Some necessary functions that are needed.
onChange (Intercept text changes): In order to capture changes made in the text editor, which is translated into CRDT Characters that can be sent to other users.
onChangeSelection (Intercept selection changes) Used to see what each user is currently selecting on their screen.
Rich-text to CRDT Sequence
Changes made to the text editor needs to be translated into its equivalence in the CRDT model. The rich text editor is a list of characters, where each character has an index. Text changes are represented as operations with index in the list, and the operation (insert, delete, bold, italic, underline, etc). This change must be translated into a list of CRDT Characters. These CRDT characters are sent between users through the server. Since the CRDTs guarantee convergence, they will be inserted into the correct index.
Once a user receives a change, it will first apply the change to its own CRDT Sequence. Then the CRDT Sequence can tell the rich text editor to apply the change to the editor.
In my implementation, I made a list of the internal CRDT Sequence, which simplified debugging. In the image below, each character in the rich-text editor is represented in the list. Each character has an index tied to it, along with bold, italic and underline properties. Whenever a user removes a character, in the editor, the index will be translated into the equivalent index in the CRDT Sequence and set the tombstone to true.

When a change occurs in the text editor, its index is translated into the indexes in the CRDT Sequence and then its inserted. Let's say we insert a character at index 5 in the editor, we will go and find which character is between index 4 and 5 in the CRDT Sequence, perhaps they have an index of 130 and 150. Then our insert will be somewhere between 130-150. This change will then be sent to all other replicas which will be able to insert the character into its editor.
When a client receives a change made by another user. It will receive a change with an index tied to the CRDT Sequence. The system will find out what index it's tied to in the actual editor and apply the change. Let's say an insert with character 'b' is applied at the CRDT index of 133, we can go over all the characters with a lower index and are still visible on the screen (tombstone is false) and make the insert at the correct position.
You can try the editor here. If you want to get into the technical details you can have a look at the source code below.
CRDT Sequence (client app written in React)
CRDT Server (server written in Node.js + Express)
Writing your own collaborative editor is difficult. Thankfully there exist open source solutions which are running in production systems. This was a fun and challenging exercise, but if you want to create products and launch fast, creating your own editor will take quite some time. I am soon launching a collaborative code editor that can be used to conduct technical interviews.
Next week I will publish an article on existing open source collaborative editors which you can use in your own projects. Subscribe to the mailing list if you are interested in more articles on this topic.