




Collaborative Editing Using CRDTs
TLDR
A collaborative editor allows users to work on a document together in real-time. In this article I look into a particular algorithm called CRDT WOOT, where I describe how it works. An application that demonstrates how it works can be found here. The code is in the github repository.
A collaborative editor allows multiple users to edit a document in real-time. Users can make changes and the document is being updated and synchronized in the background. This lets users focus on the content, and not have to worry about resolving any conflicting changes between edits. What makes this type of system interesting from a technical perspective is that conflicting updates are bound to happen, and you have to make sure they don't cause any issues in order to have a functioning collaborative editor.
I have created an editor, where users are able to work on a document together. The document is updated in real-time, and if a user loses connection, the document will be synced when a connection is re-established. Conflict Free Replicated Data-types is a collection of data types that makes it possible to solve any conflicting updates. CRDT WOOT is one of those.
A collaborative editor consists of several components, a text editor, a model which can solve any conflicting updates, and a communication layer that can send updates to and from users.
If you think of text being edited, it's easy to think in terms of indexes. For instance ABC consists of three characters, A comes first with index 0, B after A at index 1 and so on. But you soon would run into problems if two users simultaneously makes an update at the same index.
In the following image you can see two users editing a document together. Bob wants to remove a character at a position. Simultaneously Alice decides to make an insert. A problem appears because they apply the operations in different orders, which makes their copy of the document diverge into different states.
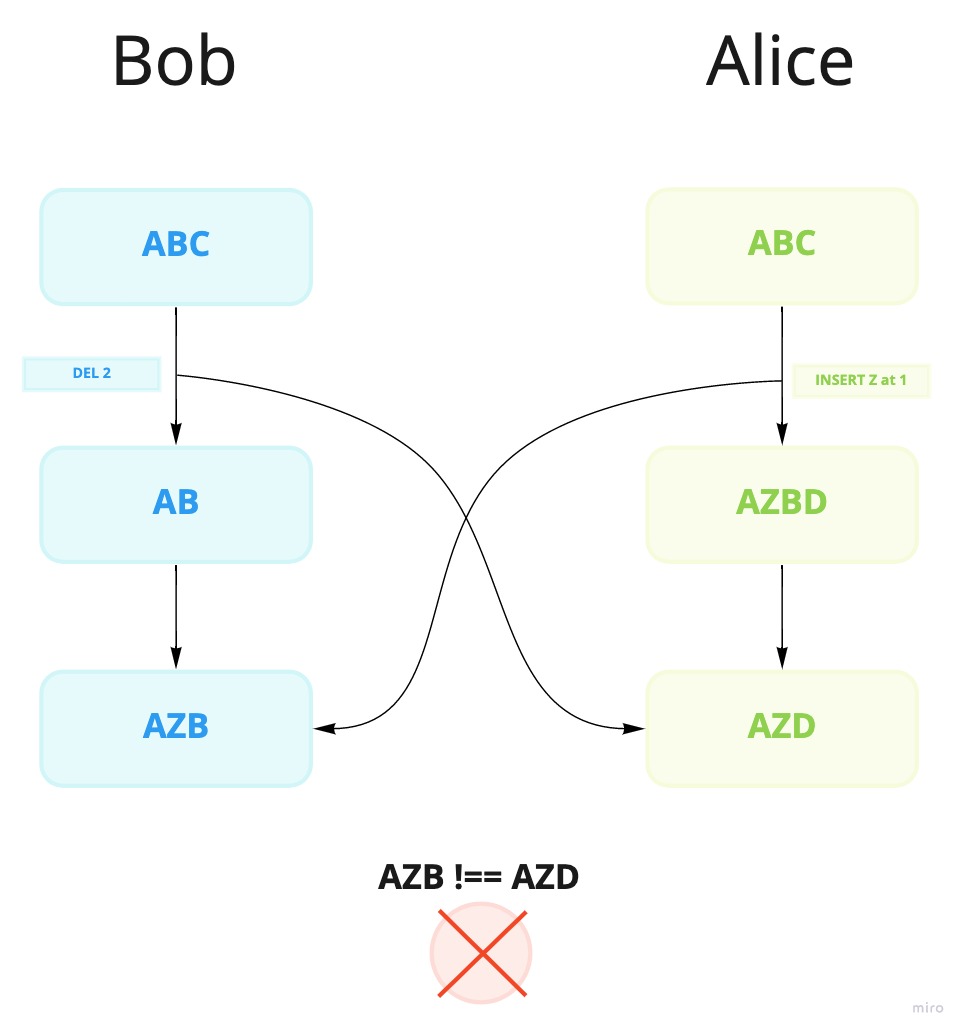
Clearly using indexes for dealing with concurrent updates wont work in this scenario. WOOT will instead describe a character by the identifier of its neighbors. So B will be described as being next to A and C, and not by any index. Still if two users add a character between A and C, then the algorithm will place one of those before the other based on identifier of the user who inserted the character.
In the following example, both users delete the same character locally first, then they send it to the each other. What happens is that both delete the same character, but when they receive the delete operation, both have already deleted that character, so both end up deleting one extra character, since now the indexes has changed. This is obviously not the desired outcome.
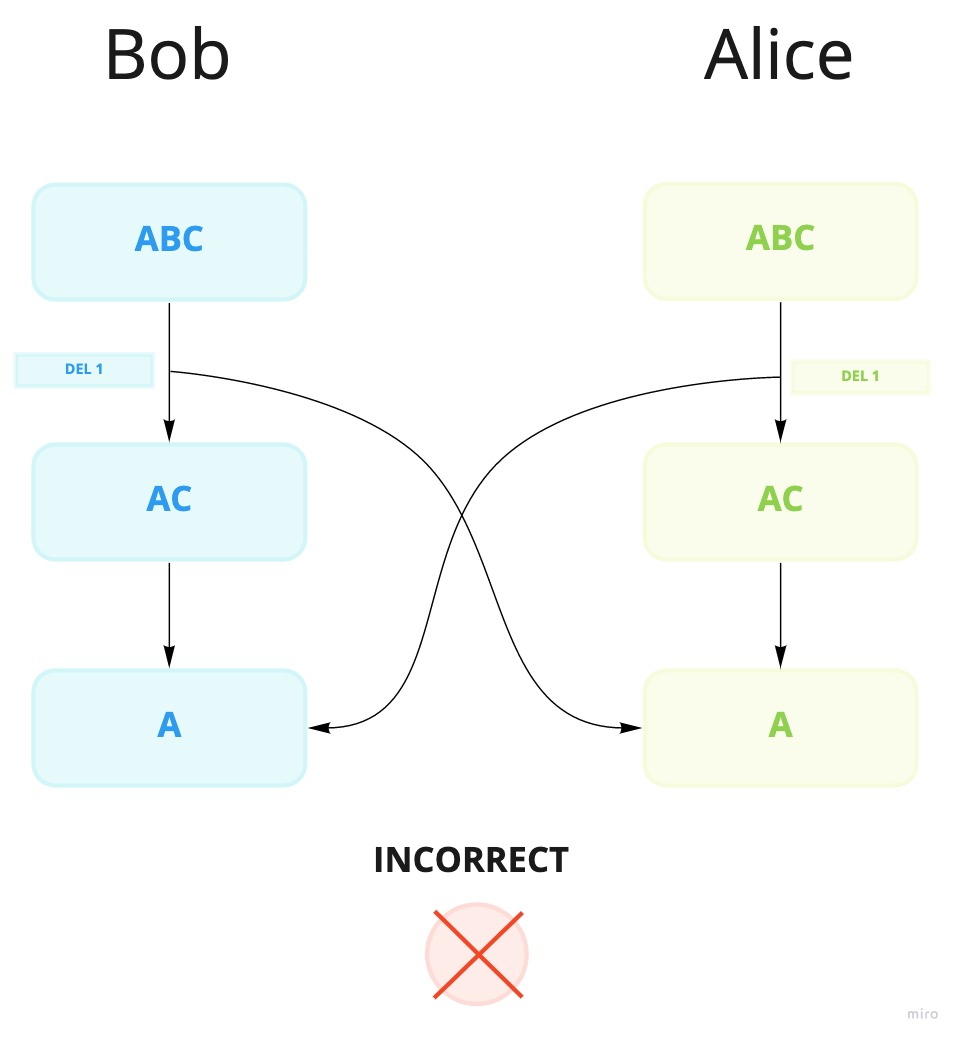
With WOOT, these kinds of concurrent updates are handled, so that the intent of the user is as expected.
Let's dig deeper.
Text editor
First of all, you need an editor that has good APIs for updating the document, such as ProseMirror, Quill.js, CodeMirror, Monaco among others. I found Quill.js to be quite easy to work with. What you need is for the editor to be easy to work it, as you need to update the document from your model in the background, and be able to separate the changes being made from the local user, and the ones incoming from other users. Fortunately, Quill.js has good support for this, but there are plenty of options. For instance CodeMirror and Monaco are specialized for editing code, so if you want to make a collaborative code editor such as VS Code Live Share, you should look into those. Monaco is the editor being used by VS Code.
The model
I have implemented CRDT WOOT, which is able to merge any conflicting updates.
What is a CRDT
A CRDT is data type that is constructed such that no conflict can occur. As long as all operations are sent to all replicas, all replicas converge to the same state eventually. CRDTs allows all replicas to communicate in a peer-to-peer network, using for example a gossip protocol. But its still useful in the case where a central server is used. The operations that are sent to each replica, can be received in any order, applied multiple times, and still converge to the same state. This is possible because all operations are commutative and idempotent. You can read more about CRDTs here.
The WOOT model satisfies the following properties:
- Convergence: When the same operations have been applied at multiple sites, the final state should be equal.
- Intention preservation: For any operation that has been applied at all sites, it will have the same effects as when it was applied in the originating site. If you have a starting state of "Hello", and Alice adds "Hello Bob", and Bob simultaneously writes "Hello, I am Bob", the final state will be "Hello Bob, I am Bob", the intention of both edits are there, they are not intertwined or interleaved.
- Causality preservation: For any pair of operations a and b, if a is causal to b, then a is executed before b at all other sites. This makes sense, if you write b after a, then a must be present for before applying b at all sites.
The algorithm describes a character the following way.
A W-character c is a five-tuple
< id, value, visible, idcp, idcn >
where
idis the identifier of the character (site id, unique natural number).valueis the alphabetical value of the character.visibleindicates if the character is visible.idcpis the identifier of the previous W-character of c.idcnis the identifier of the next W-character of c.
So the position of the character is determined by its neighboring characters, and not any numerical index. Also note that the visible boolean, which says whether or not a character has been deleted, as deleted characters are kept in the state, as tombstones. This is one downside of some CRDTs, as deleted characters needs to stay in the sequence.
The id of a character consists of the site id (id of the site that produced the character), and a natural number, which increments after every update.
The document itself is stored in a sequence of W-characters. In my implementation I used an array for this.
Definition 3 in the paper states that a character identifier is a pair (ns, ng), where ns is the id of the site and ng is a natural number. The natural number is just a local clock that increments on every change, the site id stays the same. This will later be used to know at what point in time the edit was being made. It can also be used to identify which character a certain user might be missing from the others users.
Generating an insert
To locally insert a character, all that is needed is to create W-character and add the neighboring visible characters id to idcp and idcn. Then broadcasting this operation to other sites. This operation is fairly simple. As you just need to tell the model at which index an insert has been made, then the model will have to figure out which the neighbors are, and then broadcast the operation to other sites.
Generating a delete operation
Generating a delete operation is easy, just find the character among the visible ones, and mark it as deleted and broadcast to other sites.
Integrating an insert
The tricker operation is integrating inserts from other sites. The algorithm has to find the right position between the previous and next character. There could potentially be characters that have already been added in between these two characters, or either one of them could have been removed already. The algorithm will take a subsequence of the characters between idcp and idcn, if its empty it can be inserted here. Otherwise it will sort all characters and find a smaller subsequence where the character belongs, and make a recursive call until its found its place in the sequence.
Integrating a delete operation
Integrating a delete operation is easy. The character is made invisible, and the model can count how many visible characters are in front of it in the sequence, then it can be deleted in the editor as well.
Back to the original problem
With all that in mind, lets look at some practical examples again, and see how the problems we started with can be solved with the use of CRDT WOOT.
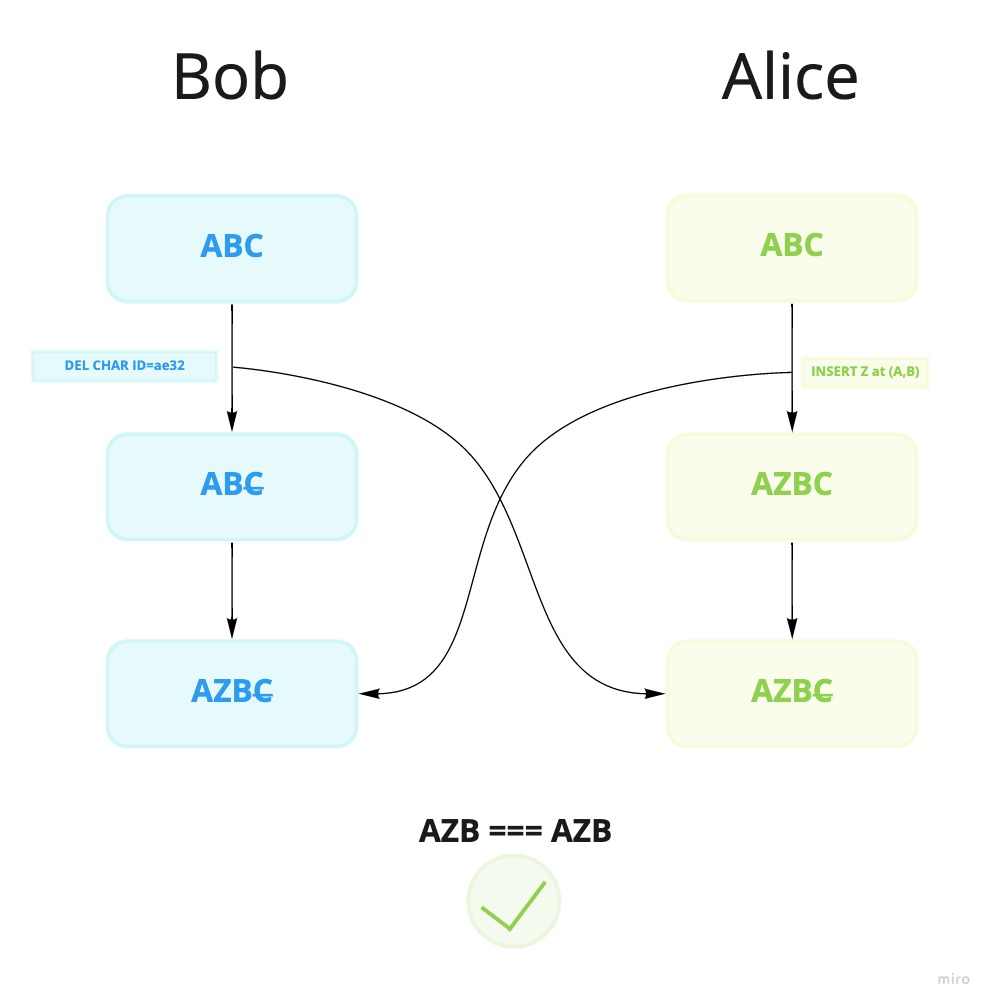
In the case were we tried to make an insert using regular indexes, we ran into issues. But now that we describe an insert operation using the identifiers of the neighboring characters, the conflicting updates will be resolved. So in the following example, we have an insert operation happening at the same time as a deletion occurs. As the operations are passed to each user, the insert and deletion happens in different orders, but since the operation is commutative, the state in the end is the same for both users.
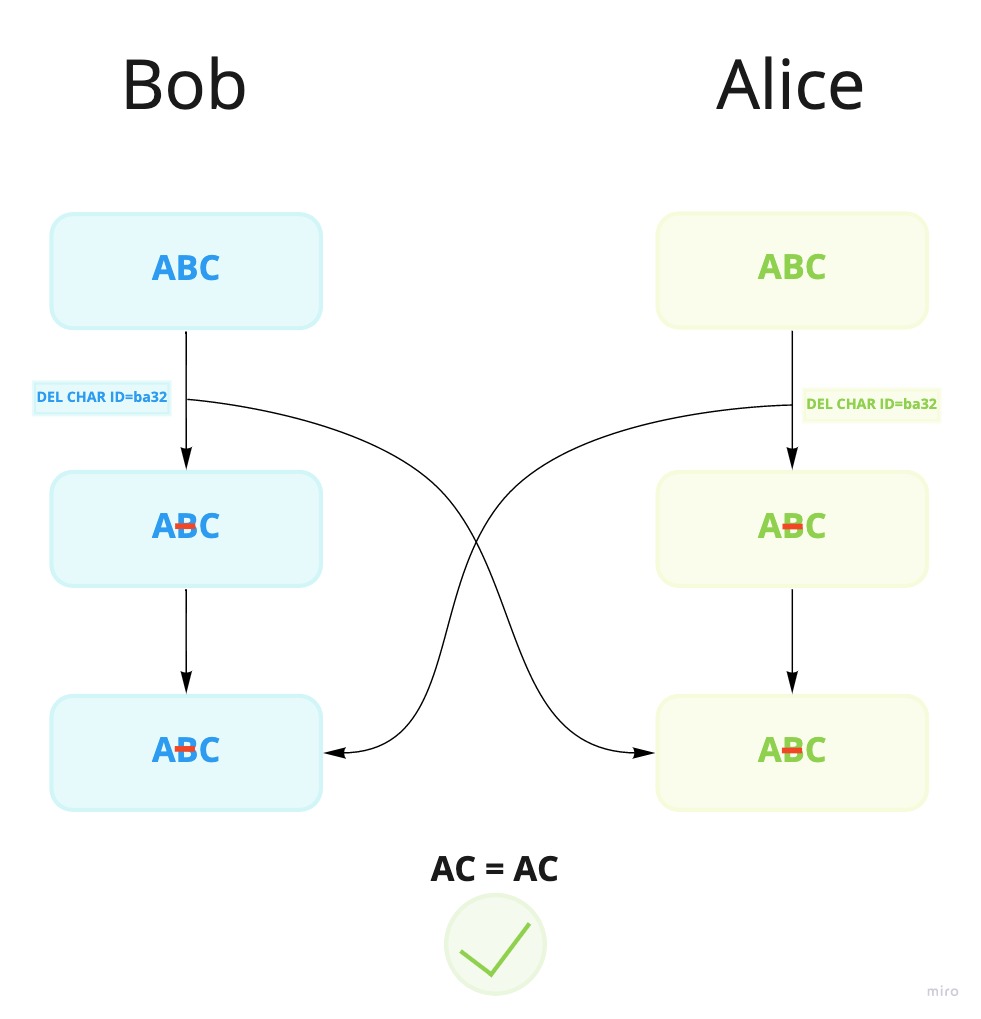
What about the case were we delete the same character. Since deletion happen when we simply set the visible boolean to false, it does not matter if two users delete the same character. As CRDTs are idempotent, any operation can be applied several times, as the state will end up the same.
Interleaving
Another interesting property that comes up when dealing with collaborative editing algorithms is something called interleaving. It can happen when multiple users are editing characters that are in close proximity to each other, where the text is intertwined when its synchronized. In such a scenario, the document look something like this.
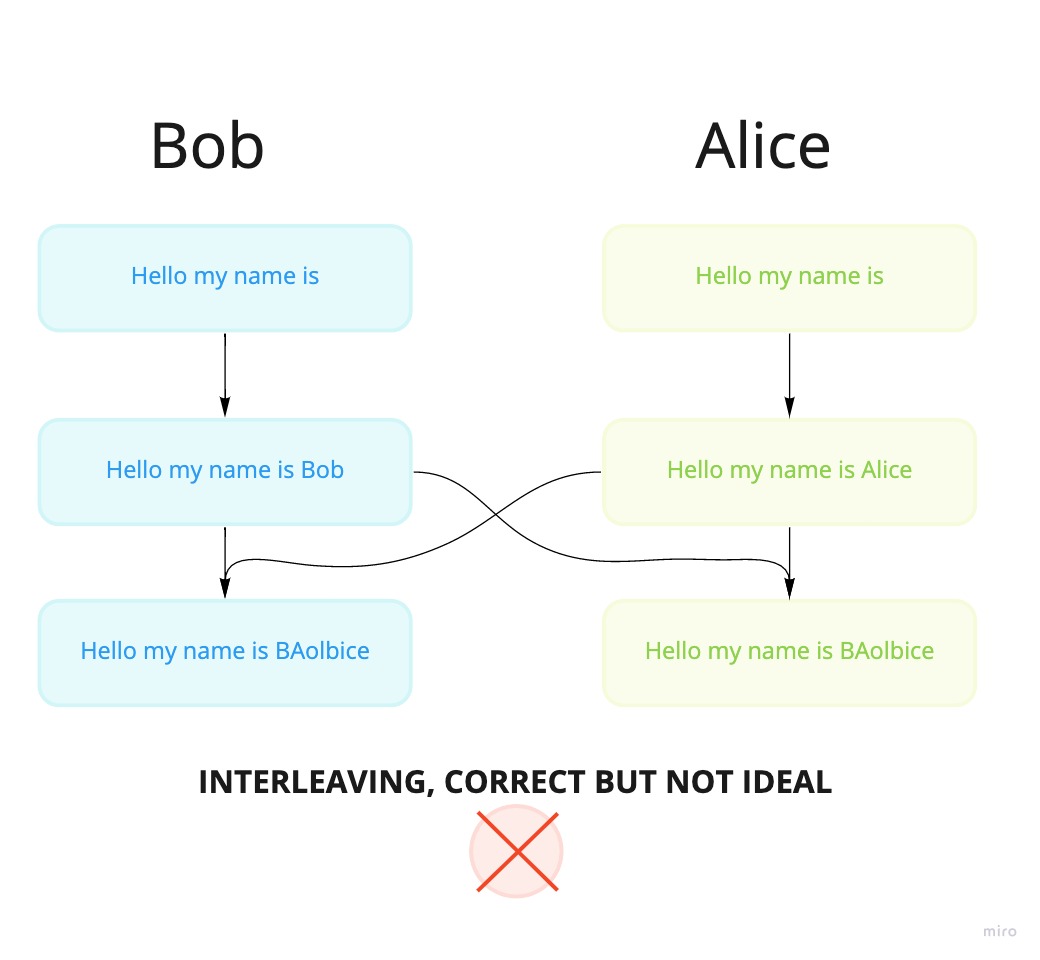
This is of course not the intent of either user, since the sentence looks really strange. But technically the document has the same state. Fortunately some algorithms can handle this problem in a better way. As stated in the paper, the WOOT algorithm supports intention preservation. Which makes the words appear one after another, as seen in the example below. Still, some user input might be needed, if the sentence doesn't make any sense any longer.
I focused on the broader concepts of WOOT in this article. But if you want to read more about WOOT, you can read the research paper here. In the github repository you can look into the implementation details of my application.
Communication layer
In order to keep all sites in sync with each other, they need to communicate and let each other know their current state. This can easily be solved by using version vectors. The version vector can be stored at each site, it will contain how many updates it has received from other sites. Bob will have his own version vector, which says how many number of updates he has received from Alice and vice versa. They can then simply just send these to each other and sync changes that way. Or a central server can keep all users up to date.
Mathematics behind CRDTs
So far I have skipped over what makes CRDTs work. CRDTs follow certain mathematical properties that ensures any potential conflicts will be resolved. If you have heard of CRDTs before, you probably have come across join semi-lattices. Which might sound intimidating, but this concept originates from order theory, which is based on simple mathematics. An order is a binary relation, for example 1 is less than 2. You can also think of it in terms of son <= father. Combine this with the commutative and idempotent properties, you will get a semi-lattice.
A good structure for explaining a join semi-lattice is by using a vector clock. Its a vector containing timestamps, each element is a number. They can look this (1,4,2). If Alice, Bob and Charlie were to write a collaborative editor, each item in the vector clock could represent the number of operations that particular user has contributed to the system. So Alice has contributed one change, Bob 4 changes and Charlie 2 changes. And each user has their own version vector, which keeps track of the changes it has. This vector clock can then be used to figure out which operations are missing in any of the users system.
This means that the vector clocks, can be different to one another, but when receiving the missing updates, the vector clocks should eventually have the same value, and the state will converge.
The following example shows how this work. From any given starting point, you simply follow the arrows and you end up in the final state. In this example you have two states, indicated by the blue circle, which can be joined by simply following the arrows to the box that joins the two. Where the two states join is where there is a least upper bound (LUB). From anywhere in this structure you can join any two states together, and a have a LUB, because the join semi-lattice is following the commutative and idempotent properties.

A join semi-lattice follows the following properties.
- Commutative:
(a ∪ b)= (b ∪ a) - Associative:
(a ∪ b) ∪ c) = (a ∪ (b ∪ c)) - Idempotent:
(a ∪ a) = a
Here, ∪ is the union operation, but it can be replaced by other binary operations, such as max, min. The version vectors above takes the maximum value of every element in the vector, in order to arrive at the desired state.
And that was a brief overview of how what makes CRDTs work.
Further improvements
In this application I have not looked into setting up any communication protocol that will send each change to other sites. But this is where one could use a gossip protocol, or a simple client-server protocol to pass changes to other users, by using the vector clocks described earlier.
Other features include adding formatting options to the editor.
That's it, you can try the application here. The code is in the github repository.